LLM Engine and Engine Core [WIP]
This section covers fundamentals of vLLM.
LLM Engine
Is the fundamental building block of vLLM. On it’s own it’s capable of delvering high throughput inference in an offline setting. But can’t serve to customers over web.
!pip install vllm -q
# Environment variables
import os
os.environ["VLLM_USE_V1"] = "1" # engine V1
os.environ["VLLM_ENABLE_V1_MULTIPROCESSING"] = "0" # running in a single process
from huggingface_hub import login
# login with hf token
# Running example
from vllm import LLM, SamplingParams
prompts = [
"Hello, You're an",
"Current state of AI"
]
model_name = "TinyLlama/TinyLlama-1.1B-Chat-v1.0"
sampling_params = SamplingParams(temperature=8.0, top_p=0.95)
llm = LLM(model=model_name) # LLM Engine
# Sample from LLM Engine
outputs = llm.generate(prompts, sampling_params)
Adding requests: 0%| | 0/2 [00:00<?, ?it/s]
Processed prompts: 0%| | 0/2 [00:00<?, ?it/s, est. speed input: 0.00 toks/s, output: 0.00 toks/s]
outputs[0]
RequestOutput(request_id=0, prompt="Hello, You're an", prompt_token_ids=[1, 15043, 29892, 887, 29915, 276, 385], encoder_prompt=None, encoder_prompt_token_ids=None, prompt_logprobs=None, outputs=[CompletionOutput(index=0, text='hd Business pleasure canción Stock Mohból vieautéścierves Democratic Zum As PelΤ', token_ids=[16440, 15197, 15377, 24174, 10224, 12929, 26976, 6316, 18560, 4255, 20098, 19083, 25174, 1094, 15549, 30414], cumulative_logprob=None, logprobs=None, finish_reason=length, stop_reason=None)], finished=True, metrics=None, lora_request=None, num_cached_tokens=0, multi_modal_placeholders={})
Rigt now the example is: synchronous, single GPU, offline(no web/distributed system scaffolding).
LLM Engine Constructor
The main components of the engine are:
- vLLM config:- contains all knobs for model, cache, parallelism.
- processor(input):- turns raw input into
EngineCoreRequestsvia validation, tokenization, and processing. - engine core client:- (Running example - InprocClient == EngineCore). Inprocessclient, can’t serve at scale. Accepts
EngineCoreRequests - processor(output): Converts raw
EngineCoreOutputs->RequestOutput.
Engine Core
Inferred: Engine Core process the tokens and returns EngineCoreOututs, So it must be responsible for forward pass, decoding.
Engine core is made up of below subcomponents:
- Model Executor(executes forward pass). Currently this is UniProc(single
workerprocess in a single GPU). - Structured Output Manager - Used for guided decoding.
- Scheduling(decides which request goes into engine in next step), it has:
- Policy(for requests) - FCFS or Priority.
- Queues: waiting, running.
- KV Cache Manager - Core of Paged Attention and vLLM.
- Maintains a
free_block_queueto manage KV blocks. KV Blocks acts as index to KV computation in Physical Memory - Index[CPU], KV computation[GPU]
- Maintains a
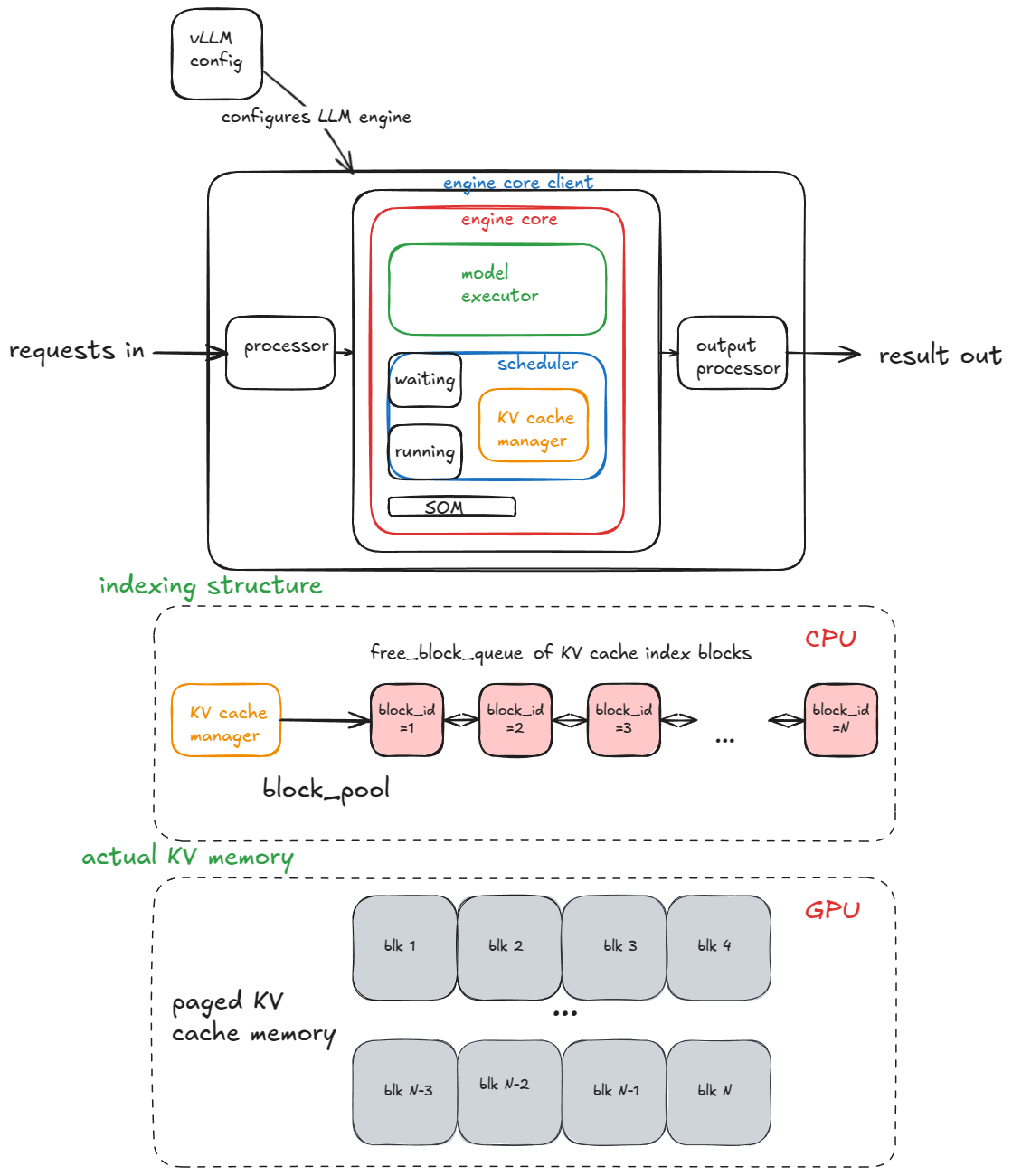
Paged Attention | Key Value Cache Manager
High Level Abstract from Paper and Inspiration.
- Using simple allocation scheeme by reserving contiguous space of memory leaves a lot of small unused memory between them. This unused memory when combined can be used to run multiple processes.
- A logical mapping layer between process and physical memory. With this logical mapping we’ve a virutal memory to work with.
-
Logical mapping: Pages[Virtual memory] –> Page Table [Page address Frame Address] –> Frames[Physical memory]. - Now virtual memory is contiguous but physical memory is non-contiguous.
Attention Bottleneck:
- In Attention, Key Value calculation is the core operation and it’s I/O bound due to memory access. It faces similar problem of contiguous memory allocation and allocation of max memory of context size at the beginning of processing a request[Text Generation]. This leaves lot’s of memory unused, ex: Generation might end at half or even quarter of context size.
- All parameters are static and loaded.
KV Cache Manager:
- Adds a KeyValue block Layer between processes and GPU to leverage it’s memory efficiently and their computation power.
- Now multiple requests can be batched together and leverage the advantages of KVCache Manager.
Model Executor
During Model Executor construction an worker object is created and three key procedures are executed. The below points across three procedures can be intutivley understood why they’re needed to sample tokens from an LLM.
These processes are independet for each worker.
1. Init Device
- Assign a CUDA device (cuda: 0) and model dtype is supported. – Hardware
- Enough VRAM is available, given the requested
gpu_memory_utilization. – Hardware - Setup distributed paralleism(Data/Model/PipelineExper).
- Instantiate a
model_runner. This holds sampler(tokens), KV Cache, and forward pass buffers(input_ids, positions etc). – Model, data, Software: Runs on GPU. - Instantiate a
InputBatchobject. This holds: – Runs on CPU.- CPU side forward pass buffers(will be passed to GPU similar to .to(device) in torch.)
- KV Cache index. Will be used by model_runner to get KV computations.
- Sampling metadata - Temperature, top_k, top_p etc.
2. Load the model
- Load model architecture.
- Load model weights.
- Set model.eval() (torch inference mode).
- torch.compile() - optional.
3. Initialize KV cache
- Get per layer KV Cache spec. KV Cache spec is how the KV cache be organized and managed per layer.
- Run a dummy/profiling forward pass run and take a snapshot of GPU memory to see how many KV Cache blocks can fit in VRAM for this model.Profiling is done to obtain data on how much memory is required for KV cache, instead of static large memory assignment, memeory assignment takes place based on profiling data.
- Once memory is allocated, tensors per layer are reshaped in allocated memory and binded with KV cache. Reshape is for ease of access blocks during forward pass.
- Prepare attention metdata (e.g flash attention etc) so that it can be used by the kernel.
- Save kernel launch latency: for every warm up batch run a dummy run and capture CUDA graphs. CUDA graphs capture entire CUDA work into DAG.Then we launch the prebaked graphs instead of launching kernels.
- These CUDA graphs essentially captrue all kernel launches, memory copies etc into DAG using a warmup batch that contains diverse set of possible batch sizes come up in inference. This include KV Cache spec for attention layers.
- These graphs are stored and later recalled during forward pass.
Generate Function
- Create a unique Request ID and capture arrival time.
- Input processor: Convert
promptinto a dictionary containingprompt,prompt_token_ids,type(text, image, audio, video). - Pack this info together with sampling params, priority, other metadata into
EngineCoreRequest. - Pass
EngineCoreRequestto engine core client. This is converted intoRequestobject and sent towaitingqueue in scheduler.
Now the request is fed and execution can begin. In synchronous run once exection starts there’s no way to inject requests mid-run. In asynchronous execution, mid-run request injection is possible. This is called continuous batching.
Generate --> Scheduler[Waiting]
Excerpts from continuous batching paper.
Continuous batching is how requests are batched in vLLM.
- All points inferred are from earlier inference systems.
- Once a batch(32) execution starts:
- Let’s say a prompt from the batch is completed and remaining are still running.
- The finished text generation has to wait until all other generation is completed. Thus increasing latency to client even though it’s completed much earlier. – Early-Finished Requests.
- Let’s say a batch is being executed and client request came dalyed by a ms before the batch execution started. The request has to wait until batch execution is completed. – Late-joining requests.
- In these systems, inference is at the granularity of requests. Communication between serving and execution takes place only to accept a new batch.
- To avoid this continous batching proposes below points:
- Execution engine returns results at every iteration(i.e after every token mint).
- Now the execution is not a request level but iteration level.
- Now Early-finished requests can be returned to client without additional latecy, Late-joining requests can be added to the batch once a request is finished in the batch.
- Batching is only applicable when the two selected requests
are in the same phase, with the same number of input tokens
(in case of the initiation phase) or with the same token index
(in case of the increment phase). (From paper)
- To overcome this, selective-batching is proposed:
- Non-matrix multiplication, Lineary Layer Norm, Gelu can be flattened and forward pass can run even when the token lengths are not the same within the batch. This is just computation until attention. This is essentially batching the requests until attention to utilize GPU to it’s fullest.
- vLLM or inference engine tracks tokens with their requests.
- At attention each requests are processed without batch. Because attenion can’t tend to tokens from other requests.
- Now we’ve selective batching.
- To overcome this, selective-batching is proposed:
- Execution engine returns results at every iteration(i.e after every token mint).
- With Iteration level returns and selective batching, now more requests can be processed with reduced Latency.
Engine Step()
Now the requests are in engine(Generate Function), as long as there are requests engine repeatedly calls step(). Each step has three step:
- Schedule: Select requests to run in this step(decode and/or prefill).
- Run forward pass and sample tokens.
- Post-Process: append sampled token IDs to respective
Request. Detokenize and check for stop conditons. If stopped clean up(like cleaning KV cache blocks).
Stop conditions are:
- max_length is reached.
- sampled token is eos, unless
ignore_eosis enabled. - If sampled token is in
stop_token_idsin sampling params. - stop strings are present in output. Stop strings will not be included in output wheres stop_token_ids will.
Scheduler
There are two types of workloads an inference engine handles:
- Prefill: Process all prompt tokens in a single forward pass and samples a single token from the logits. Workload: Compute-bound(Why?) all matrix multiplications has to be performed for all prompt tokens.
- Decode: Runs forward pass for sampled token, previous token computations are stored in KV cache. Workfload: Memeory-bandwidth-bound(Why?) model weights and KV caches has to be loaded to compute a single token.
The scheduler prioritizes decode request:- requests in running queue: For each request below steps are run:
- Computes the number of tokens to generate(not always 1 due to speculated decoding and async scheduling)
- call’s KV Cache manager’s
allocate_slots()function. - Updates token budget by subracting tokens from step 1.
After that is processes prefill requests from waiting queue:
- Retrieves number of computed blocks(0 if prefix caching is disabled)
- call’s KV Cache manager’s
allocate_slots()function. - Pops request from waiting queue and moves it to running queue.
allocate_slots()
- Calculate number of blocks: number of tokens / block size(number of tokes a block can store).
- Availability of blocks: Checks if calculated number of blocks are available. If not, below are the possible options:
- recompute preemption(available blocks) by evicting low-priority requests.
- skips scheduling and continue execution.
- Allocate blocks: via KV cache manager co-ordinator fetches first
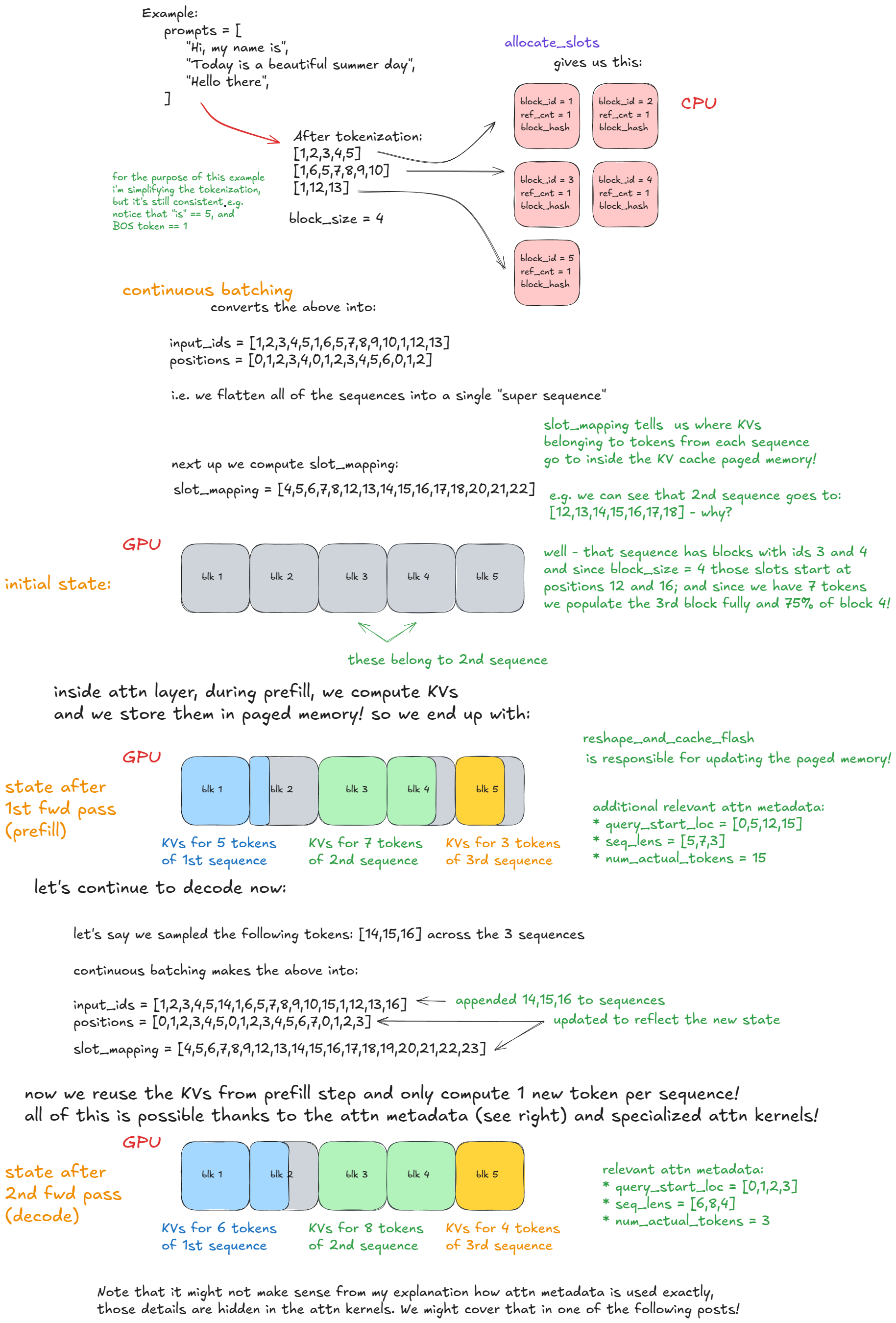
nblocks fromfree_block_queue. Store blocks and request mapping inreq_to_blocks. This dictionay maps eachrequest_idto their blocks. Let’s say there are 14 tokens with block size = 4, block id 1,2,3 will be
Forward
model executor’s execute_model() is called, this delegates to worker in turn delegates to model_runner. Below are the main steps of model_runner:
- Prune requests: Remove finished requests from
input_batch, update fwd pass related metadata(ex: kv blocks associated with the request). - Prepare inputs: Move input buffers from InputBatch(CPU) -> model_runner, map block ids(allocate_slots()) to blocks(slot_mapping), construct metadata.
- Forward pass: All requests are batched into a single super long sequence, differentiated by position indices and attention masks. This enables continuous batching without right padding.
- Gather last token hiddens states and compute logits.
- Use logits to sample a token based on parameters(top_k, top_p etc).
Overall Flow(Forward pass: Continuos batching and paged attention)
Steps 1-5: CPU Steps 6 and above: GPU
- requests arrives into vLLM, tag a request_id.
- Input Processor processes the raw text, tokenizes and packs it into EngineCoreRequest.
- EngineCoreRequest –> engine_client –> Request –> Place in Waiting Queue.
- Scheduler picks up requests(processed inputs - either prefill or decode) in waiting queue.
- allcote_slots() - kv block ids and stores them as key value pair in req_to_blocks.
- model_runner
- converts this into a single long sequence for continuous batching and moves it into cpu.
- slot_mapping() - maps block ids to actual blocks in gpu.
- Compute kv’s and store them in blocks.
- prefill done
- decode, sample a token, uses kv cache instead of computing the kv for entire sequence.
- append it to single long sequence
- update blocks