Quantization For Retrieval
In this notebook, we’ll try to improve the embedding retrieval score of qwen-gte-7B embedding model for paul graham dataset.
!pip install python-dotenv llama-index sentence-transformers "ray[data, train, tune, serve]" pydantic_numpy accelerate -q
[2K [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━[0m [32m207.5/207.5 MB[0m [31m4.2 MB/s[0m eta [36m0:00:00[0m
[?25h
Quantization and Distillation
This notebook combines quantization, distillation with evaluation.
Source notebooks or Pre-reads(might not be a word lol):
This notebook:
- Mainly focuses on putting together various concepts into neat reusable components of software.
- Quantization works for int8, int16 dtypes.(W8A32, W16A32).
- Uses Synthetic QA dataset generation from llama index.
- Generic Evaluation setup and QA Retrieval Evaluation setup.
- Retrieval Evaluation setup is built for single and batch modes.
# Imports
import time
import json
import os
import torch
from pathlib import Path
import json
from llama_index.core.evaluation import EmbeddingQAFinetuneDataset
from abc import abstractmethod
from dotenv import load_dotenv
from sentence_transformers import SentenceTransformer
from transformers import AutoModel, AutoTokenizer, AutoConfig
from sentence_transformers.util import cos_sim
from typing import Union, Dict, List
from tqdm import tqdm
import torch
import torch.nn as nn
import torch.nn.functional as F
from pydantic import BaseModel
import numpy as np
import pydantic_numpy.typing as pnd
from uuid import uuid4
from pymongo import MongoClient
import gc
# Variables
os.environ["TOKENIZERS_PARALLELISM"] = "false"
if "COLAB_JUPYTER_TRANSPORT" in os.environ:
LLAMA_INDEX_DIR = "<INDEX DIR>"
DATA_DIR = os.path.join(LLAMA_INDEX_DIR, "exp1")
SECRETS_PATH = "<SECRETS_PATH>"
else:
DATA_DIR = "dataset/"
SECRETS_PATH = "../env/env.local"
ORIGINAL_WEIGHTS = "original_weights.pt"
QUANTIZED_WEIGHTS = "quantized_attention.pt"
# Load secrets
load_dotenv(SECRETS_PATH)
# Define Evaluation Dataset
dataset_path = os.path.join(DATA_DIR, "qa_dataset_all.json")
model_path = "Alibaba-NLP/gte-Qwen2-7B-instruct"
# Using localhost mongo without security
DATABASE_NAME = "embeddings"
COLLECTION_NAME = "paul_graham"
Quantization Helpers
# Implementation details - https://colab.research.google.com/drive/1KrA705bUNNPDpJ1f_1sChStuFkqhbJy9#scrollTo=3jFpCNz6KcnP
# Quantization setup
# This is 1.5B model, hence LinearQuantization will work as outliers have an impact post 6.7B at scale.
def forward(weights, inputs, scales, zero_point=None, bias=None):
"""
Forward pass of W8A32 or W16A32 Linear Layer. This function accepts weights, inputs(hidden state activations), scales and optional bias.
"""
casted_weights = weights.to(inputs.dtype)
if zero_point is not None:
# Full range quantization
dq_output = (casted_weights - zero_point.unsqueeze(1)) * scales.unsqueeze(1)
output = F.linear(inputs, dq_output)
return output
# Linear operation on input and weights
output = F.linear(inputs, casted_weights) * scales
if bias is not None:
output = output + bias
return output
class W8A16LinearLayerV1(nn.Module):
def __init__(self, in_features: int, out_features: int, bias: bool = True, device=None, dtype=torch.int8) -> None:
super().__init__()
self.dtype = dtype
self.q_max = torch.iinfo(self.dtype).max
self.q_min = torch.iinfo(self.dtype).min
# Weights
self.register_buffer(
"int_weights",
torch.randint(low=self.q_min, high=self.q_max, size=(out_features, in_features), dtype=self.dtype)
)
# Scales
self.register_buffer(
"scales",
torch.randn(out_features, dtype=torch.float32)
)
# Zero point
self.register_buffer(
"zero_point",
torch.randn(out_features, dtype=torch.float32)
)
if bias:
self.register_buffer("bias", torch.randn(1, out_features, dtype=torch.float32))
else:
self.bias = None
# Forward pass
def forward(self, inputs):
return forward(
weights=self.int_weights,
inputs=inputs,
scales=self.scales,
bias=self.bias,
zero_point=self.zero_point
)
def quantize_absmax(self, weights,):
w_fp32 = weights.clone().to(torch.float32)
# Create scales
scales = w_fp32.abs().max(dim=-1).values / self.q_max # Per channel scales
scales = scales.to(weights.dtype)
int_weights = torch.round(w_fp32 / scales.unsqueeze(1)).to(self.dtype) # Unsqueeze is to resize scales as row vector
self.int_weights = int_weights
self.scales = scales
self.zero_point = zero_point
return int_weights, scales
def quantize_fullrange(self, weights,):
w_fp32 = weights.clone().to(torch.float32)
t_max, t_min = w_fp32.max(dim=-1).values, w_fp32.min(dim=-1).values
scales = (t_max - t_min) / (self.q_max - self.q_min)
zero_point = ((self.q_min - t_min) / scales)
# Zero point edge case
zero_point[zero_point < self.q_min] = self.q_min
zero_point[zero_point > self.q_max] = self.q_max
# quantize weights
int_weights = torch.round((w_fp32 / scales.unsqueeze(1)) + zero_point.unsqueeze(1)).to(self.dtype)
self.int8_weights = int_weights
self.scales = scales
self.zero_point = zero_point
return int_weights, scales
def replace_linear_layer_with_target_and_quantize(
module: nn.Module,
target_class: W8A16LinearLayerV1,
exclude: List,
strategy: str,
dtype = torch.int8,
):
"""
Accept a model and replace nn.Linear Layers in module with target_calss(W8A16LinearLayer)
Strategies: abxmax, fullrange.
"""
assert strategy in ["absmax", "fullrange"]
for name, layer in module.named_children():
if isinstance(layer, nn.Linear) and not any([x == name for x in exclude]):
old_bias = layer.bias
old_weight = layer.weight
new_module = target_class(
in_features=layer.in_features,
out_features=layer.out_features,
bias=layer.bias is not None,
dtype=dtype,
)
# Save memory
delattr(layer, "bias")
delattr(layer, "weight")
setattr(module, name, new_module)
if strategy == "abxmax":
getattr(module, name).quantize_absmax(old_weight)
else:
getattr(module, name).quantize_fullrange(old_weight)
if old_bias is not None:
getattr(module, name).bias = old_bias
else:
replace_linear_layer_with_target_and_quantize(
layer,
target_class,
exclude,
strategy,
dtype,
)
# Replace layers
from typing import List
def replace_linear_layer_with_target(
module: nn.Module,
target_class: W8A16LinearLayerV1,
exclude: List,
dtype=torch.int8,
):
"""
Accept a model and replace nn.Linear Layers in module with target_calss(W8A16LinearLayer)
Args:
module(nn.Module): Model.
target_class(nn.Module): Target class to replace nn.Linear.
exclude(List): List of modules to exclude from replacement.
"""
for name, layer in module.named_children():
if isinstance(layer, nn.Linear) and not any([x == name for x in exclude]):
# Get bias from layer
old_bias = layer.bias
# Create target class to replace
new_module = target_class(
in_features=layer.in_features,
out_features=layer.out_features,
bias=layer.bias is not None,
dtype=dtype,
)
# Replace
setattr(module, name, new_module) # Replace name in module with new_module
# Explicitly set bias
if old_bias is not None:
getattr(module, name).bias = old_bias
# Recursive call for Nested Modules(Ex: Multi-Attention-Head)
else:
replace_linear_layer_with_target(
layer,
target_class,
exclude,
dtype,
)
exclude = ["lm_head", "rotary_emb"]
def quantize_and_store(model_path, exclude=["lm_head"], weights_name="quantized_attention.pt", dtype=torch.int8, device=None):
if weights_name in os.listdir():
print(f"Quantized weights are alread present: {weights_name}")
print("Loading weights onto model!")
if weights_name not in os.listdir():
# Load original model and quantized model
original_model = AutoModel.from_pretrained(model_path)
replace_linear_layer_with_target_and_quantize(
module=original_model,
target_class=W8A16LinearLayerV1,
exclude=exclude,
strategy="fullrange",
dtype=dtype,
)
torch.save(original_model.state_dict(), weights_name)
del original_model
gc.collect()
# Load quantized weights and verify
if weights_name in os.listdir():
config = AutoConfig.from_pretrained(model_path)
with torch.device("meta"):
quantized_model = AutoModel.from_config(config)
replace_linear_layer_with_target(
module=quantized_model,
target_class=W8A16LinearLayerV1,
exclude=exclude,
)
if device:
quantized_model.to_empty(device=device)
quantized_model.load_state_dict(torch.load(weights_name), strict=True, assign=True)
return quantized_model
quantized_model.load_state_dict(torch.load(weights_name), strict=True, assign=True)
return quantized_model
Evaluation Setup
- Cosine Similarity(Btw Context and Questions). Inline with the objective of obtaining an smaller size and improved embedding model for the dataset in hand.
- Memory Footprint
- Latency
Dataset
I already have a synthetic Toy Dataset with works of paul Graham.
- Chunk Size - 256
- Chunk Overlap - 20
- Questions per Chunk - 2
- Total Number of chunks - 83
- Total Question/Context pairs - 166
qa_ds = EmbeddingQAFinetuneDataset.from_json(dataset_path)
class PerformanceBenchmark:
def __init__(self, model, dataset, batch_size) -> None:
self.model: SentenceTransformer = model
self.dataset: EmbeddingQAFinetuneDataset = dataset
self.batch_size = batch_size
@abstractmethod
def compute_score(self):
# Implmentation for the problem at hand
pass
def compute_size(self):
# Store the state dict, weight matrices and calculate the memory footprint
# This is relevant for PyTorch implementations for other frameworks override the method
state_dict = self.model.state_dict()
tmp_path = "tmp.pt"
torch.save(state_dict, tmp_path)
size = Path(tmp_path).stat().st_size / 1024 / 1024 # MB
os.remove(tmp_path)
return f"{round(size, ndigits=2)} MB"
@abstractmethod
def compute_latency(self):
# Implmentation for the problem at hand
pass
# Evaluation utils
class QAPairWithMetadata(BaseModel):
uuid: str
model_name: str
query: str
context: str
query_embedding: pnd.Np2DArray
context_embedding: pnd.Np2DArray
similarity: float
query_latency: float
context_latency: float
def model_dump(self, **kwargs):
d = super().model_dump(**kwargs)
d["query_embedding"] = d["query_embedding"].tolist()
d["context_embedding"] = d["context_embedding"].tolist()
return d
class QAPairs(BaseModel):
qa_pairs: List[QAPairWithMetadata] = []
class QAMetric(BaseModel):
latency: tuple
score: float
size: str
model_name: str
uuid: str
class QAMetrics(BaseModel):
metrics: List[QAMetric]
class EmbeddingBenchMark(PerformanceBenchmark):
def __init__(self, model, tokenizer, dataset, batch_size, model_name, strategy = "local", batch=False) -> None:
"""
Run Benchmarks for evaluation of embedding model
Args:
1. model(nn.Module): Embedding model to evaluate
2. tokenizer: Tokenizer associated with model
3. dataset: EmbeddingFineTuneQADataset(llama_index) to evaluate embeddings
4. batch_size: Batch Size
5. strategy: Strategy to store results. local stored in memory, mongo stores in mongodb. local crashes with models greater than 1.5b parameters.
"""
super().__init__(model, dataset, batch_size)
self.model = model
self.tokenizer = tokenizer
self.model_name = model_name
self.strategy = strategy
self.eval_results = QAMetrics(metrics=[])
# This stores results of all evaluations, might consume lots of memory for large dataset
self.qa_pairs_metadata: Union[str, List[QAPairWithMetadata]] = {}
# Individual instance of qa pairs
self._qa_pairs()
# Track runs
self.runs = {}
self.num_pairs = len(self.qa_pairs)
self.embedding_gen = self._unpack_batch_gen if batch else self._process_pair_gen
# UUID for each run
self.uuid = str(uuid4())
def _qa_pairs(self):
# Use self.dataset: EmbeddingQAFinetuneDataset
"""
Creates (question, context) pairs from EmbeddingQAFinetuneDataset.
"""
self.qa_pairs = [
(clean_and_format_text(self.dataset.queries[query_id]), clean_and_format_text(self.dataset.corpus[rdoc_id]))
for query_id in list(self.dataset.queries.keys())
for rdoc_id in list(self.dataset.relevant_docs[query_id])
]
return self.qa_pairs
def generate_embedding(self, text: Union[str, List[str]]) -> torch.Tensor:
"""
Generate embeddings for text or list of documents.
"""
with torch.no_grad():
# Tokenize
inputs = self.tokenizer(text, padding=True, truncation=True, return_tensors="pt")
# Get embeddings
output = self.model(**inputs)
attention_mask = inputs.attention_mask
last_hidden_states = output.last_hidden_state
# Check if text is padded at text beginning
left_padding = (attention_mask[:, -1].sum() == attention_mask.shape[0])
if left_padding:
return last_hidden_states[:, -1].numpy()
else:
# Get last token - sequence length
sequence_lengths = attention_mask.sum(dim=1) - 1
# Get number of inputs
batch_size = last_hidden_states.shape[0]
return last_hidden_states[torch.arange(batch_size, device=last_hidden_states.device), sequence_lengths].numpy()
def timeit(self, start_time, end_time):
return end_time - start_time
def _process_pair_gen(self, num_samples=100, save=True, **kwargs):
"""
Processes query-context pairs to generate embeddings and calculate similarity scores.
This function iterates through query-context pairs obtained from the `qa_pairs` generator.
For each pair, it generates embeddings using the model and calculates the cosine similarity between them.
"""
skip = kwargs.get("skip", 0)
self.uuid = kwargs.get("uuid", self.uuid)
for idx in tqdm(range(skip, num_samples), desc="Create, time embeddings and calculate similarity"):
question, context = self.qa_pairs[idx]
# Question embedding with timings
start_time = time.perf_counter()
query_embedding = self.generate_embedding(question)
end_time = time.perf_counter()
query_latency = self.timeit(start_time, end_time)
# Context embedding with timings
start_time = time.perf_counter()
context_embedding = self.generate_embedding(context)
end_time = time.perf_counter()
context_latency = self.timeit(start_time, end_time)
# Calulate similarity
similarity = cos_sim(query_embedding, context_embedding)
# Store query, context, query_embedding, context_embeddings, latencies, similarity to BatchedQAEmbedding
qa_pair_mdata = QAPairWithMetadata(
uuid=self.uuid,
model_name=self.model_name,
query=question,
context=context,
query_embedding=query_embedding,
context_embedding=context_embedding,
similarity=similarity,
query_latency=query_latency,
context_latency=context_latency,
)
yield qa_pair_mdata
def _batched_qa_paris_gen(self, **kwargs):
"""
Creates a generator of batch_size for _qa_pairs.
"""
skip = kwargs.get("skip", 0)
for i in range(skip, len(self.qa_pairs), self.batch_size):
questions = [query for query, _ in self.qa_pairs[i : i + self.batch_size]]
contexts = [context for _, context in self.qa_pairs[i : i + self.batch_size]]
yield questions, contexts
def _process_batch_gen(self, **kwargs) -> Union[List, int]:
"""
Processes batches of query-context pairs to generate embeddings and calculate similarity scores.
This function iterates through batches of query-context pairs obtained from the `batched_qa_paris` generator.
For each pair, it generates embeddings using the model and calculates the cosine similarity between them.
The results, including the query, context, embeddings, and similarity score, are stored in a list.
Args:
self: The instance of the class containing this function.
Returns:
Tuple[List[Dict], int]: A tuple containing:
- A list of dictionaries, where each dictionary represents a query-context pair and includes:
- "query": The query string.
- "context": The context string.
- "query_embedding": The embedding of the query.
- "context_embedding": The embedding of the context.
- "similarity": The cosine similarity between the query and context embeddings.
- The total number of query-context pairs processed (ds_size).
"""
skip = kwargs.get("skip", 0)
ds_size = 0
for query_batch, context_batch in self._batched_qa_paris_gen(skip=skip):
ds_size += len(query_batch) # For fine-grained
# Create batch embeddings
q_start_time = time.perf_counter()
query_embedding = self.generate_embedding(query_batch)
q_end_time = time.perf_counter()
c_start_time = time.perf_counter()
context_embedding = self.generate_embedding(context_batch)
c_end_time = time.perf_counter()
# Calculate similarity
similarity = cos_sim(query_embedding, context_embedding)
scores = torch.diagonal(similarity)
yield query_batch, context_batch, query_embedding, context_embedding, scores, self.timeit(q_end_time, q_start_time), self.timeit(c_end_time, c_start_time)
def _unpack_batch_gen(self, **kwargs):
skip = kwargs.get("skip", 0)
for query_batch, context_batch, query_embedding, context_embedding, scores, q_time, c_time in self._process_batch_gen(skip=skip,):
for query, context, qe, ce, score in zip(query_batch, context_batch, query_embedding, context_embedding, scores):
print(score)
qa_pair_mdata = QAPairWithMetadata(
uuid=self.uuid,
model_name=self.model_name,
query=query,
context=context,
query_embedding=np.expand_dims(qe, axis=0),
context_embedding=np.expand_dims(ce, axis=0),
similarity=score.item(),
query_latency=q_time,
context_latency=c_time,
)
yield qa_pair_mdata
def compute_latency(self, uuid):
benchmark_mdata = self.qa_pairs_metadata[uuid]
num_latencies = len(benchmark_mdata)
query_latencies = list(map(lambda x: x.query_latency, benchmark_mdata))
context_latencies = list(map(lambda x: x.context_latency, benchmark_mdata))
return round((sum(query_latencies) / num_latencies), 2), round((sum(context_latencies) / num_latencies), 2)
def compute_score(self, uuid,):
scores = list(map(lambda x: x.similarity , self.qa_pairs_metadata[uuid]))
return round(sum(scores) / len(scores), 2)
def insert_mongo(self, mdata):
with MongoClient() as client:
db = client[DATABASE_NAME]
collection = db[self.collection]
collection.insert_one(mdata)
def fetch_mongo(self, query):
results = []
with MongoClient() as client:
db = client[DATABASE_NAME]
collection = db[self.collection]
document_count = collection.count_documents(query)
if document_count == 0:
raise Exception(f"No documents found for {query}")
cursor = collection.find(query)
print("Fetching documents from mongo")
for document in cursor:
results.append(QAPairWithMetadata(**document))
self.qa_pairs_metadata[query["uuid"]] = results
print(len(self.qa_pairs_metadata[query["uuid"]]))
return self.qa_pairs_metadata
def run(self, num_samples, uuid, skip, collection=None, **kwargs):
if self.model_name in self.runs:
if skip:
print(f"Running {uuid} run from {skip}")
else:
print(f"{self.model_name}-{uuid} is already completed! Use a new model_name.")
import sys
sys.exit()
if self.strategy == "mongo":
assert collection is not None, f"Pass MongoDB Collection name to store results!"
self.collection = collection
for benchmark_data in self.embedding_gen(num_samples=num_samples, uuid=uuid, skip=skip):
self.insert_mongo(benchmark_data.model_dump())
elif self.strategy == "local":
os.makedirs(uuid, exist_ok=True)
for idx, benchmark_data in enumerate(self.embedding_gen(num_samples=num_samples, uuid=uuid, skip=skip)):
with open(f"{self.run_dir}/{self.uuid}-{idx}.json", "w") as f:
f.write(benchmark_data.model_dump())
self.runs[self.model_name] = uuid
return uuid
def load(self, uuid, collection=None):
if uuid in self.qa_pairs_metadata:
return
if self.strategy == "mongo":
print("Mongo")
assert collection is not None, f"Pass MongoDB Collection name to store results!"
query = {"uuid": uuid, "model_name": self.model_name}
self.fetch_mongo(query) # Puts all data into self.qa_metdata_pairs
elif self.strategy == "local":
print("local")
results = []
files = os.listdir(self.run_dir)
for file in files:
with open(f"{uuid}/{file}", "r") as f:
data = json.loads(f.read())
results.append(QAPairWithMetadata(**data))
self.qa_pairs_metadata[uuid] = results
def eval(self, uuid, skip):
uuids = list(map(lambda x: x.uuid, self.eval_results.metrics))
model_names = list(map(lambda x: x.uuid, self.eval_results.metrics))
if (self.model_name in model_names or uuid in uuids) and not skip:
print(f"{self.model_name}-{uuid} is already evaluated and results are available in eval_results!")
import sys
sys.exit()
benchamrk = {
"latency": self.compute_latency(uuid=uuid),
"score": self.compute_score(uuid=uuid),
"size": self.compute_size(),
}
benchamrk.update({"model_name": self.model_name})
benchamrk.update({"uuid": uuid})
metric = QAMetric(**benchamrk)
self.eval_results.metrics.append(metric)
return benchamrk
def evaluate(self, save=True, model_name=None, **kwargs):
EVAL_RESULTS = "eval_results.json"
# Collect kwargs
num_samples = kwargs.get("num_samples", 100)
self.collection = kwargs.get("collection", None)
self.model_name = model_name or self.model_name
skip = kwargs.get("skip", 0)
uuid = kwargs.get("uuid", None)
# skip run
if skip != 0:
assert uuid is not None, f"Skip run requires it's uuid to resume!"
# Normal run + eval
uuid = self.uuid if uuid is None else uuid
eval = kwargs.get("eval", False)
model = kwargs.get("model", None)
if model:
self.model = model
if eval and uuid:
self.load(uuid=uuid, collection=self.collection)
self.eval(uuid=uuid, skip=skip)
return self.eval_results
print(f"Running eval for {self.model_name} - {uuid}")
self.run(num_samples=num_samples, uuid=uuid, skip=skip, collection=self.collection)
self.load(uuid=uuid, collection=self.collection)
result = self.eval(uuid=uuid, skip=skip)
if save:
if EVAL_RESULTS in os.listdir():
print(f"Previous evaluation result exists, overwriting.")
with open(EVAL_RESULTS, "r") as f:
current_result = json.load(f)
current_metric = QAMetrics.model_validate_json(current_result)
current_metric.metrics.append(QAMetric(**result))
with open(EVAL_RESULTS, "w") as f:
f.write(current_metric.model_dump())
else:
with open(EVAL_RESULTS, "w") as f:
f.write(current_metric.model_dump())
return self.eval_results, self.uuid
Establish Baseline, Quantize, Evaluate
We’ll use gte-Qwen2-7B Instruct model for this implementation due to it’s size.
if torch.mps.is_available():
device = "mps"
else:
device = "cpu"
# Using CPU
from transformers import AutoModel, AutoTokenizer
gte_qwen_2_15b = AutoModel.from_pretrained(model_path)
tokenizer = AutoTokenizer.from_pretrained(model_path)
Sliding Window Attention is enabled but not implemented for `sdpa`; unexpected results may be encountered.
Loading checkpoint shards: 0%| | 0/7 [00:00<?, ?it/s]
# Tokenize
text = "Hello"
inputs = tokenizer(text, padding=True, truncation=True, return_tensors="pt")
# Get embeddings
last_hidden_states = gte_qwen_2_15b(**inputs)
last_hidden_states.last_hidden_state.shape
torch.Size([1, 1, 3584])
embedding_benchv1 = EmbeddingBenchMark(gte_qwen_2_15b, qa_ds, 2, strategy="mongo", model_name=model_path)
embedding_benchv1.evaluate(
name="baseline",
save=False,
model=gte_qwen_2_15b,
num_samples=len(embedding_benchv1.qa_pairs),
collection=COLLECTION_NAME,
uuid="795f3ca7-d15a-42d2-9a91-603327205ecb",
)
{'baseline': {'latency': (62.18, 63.09),
'score': 0.38,
'size': '26966.673791885376 MB'}}
Baseline is pretty poor with latencies around a minute, sim score mean of 0.4 and huge memory footprint of 27GB.
Let’s quantize, fine-tune, distill yall.!
Quantization
weights = gte_qwen_2_15b.state_dict()["layers.0.self_attn.v_proj.weight"]
weights.shape
torch.Size([512, 3584])
flattened_weights = weights.flatten()
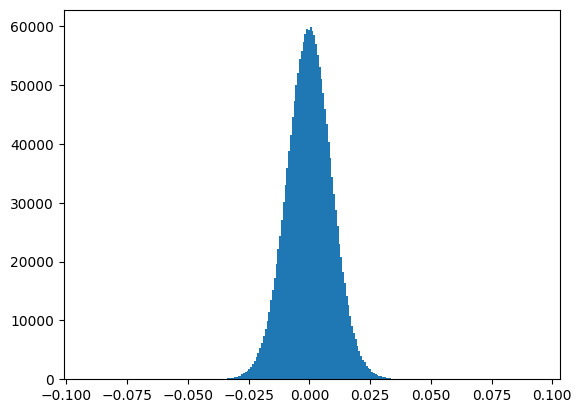
print(f"Min: {flattened_weights.min()}, Max: {flattened_weights.max()}")
Min: -0.09187449514865875, Max: 0.09371411800384521
import matplotlib.pyplot as plt
plt.hist(flattened_weights.cpu(), bins=250)
plt.show();
import numpy as np
percentiles = np.round(np.percentile(flattened_weights.cpu(), [0, 25, 50, 75, 90, 95, 99, 100]), decimals=2)
percentiles
array([-0.09, -0.01, 0. , 0.01, 0.01, 0.02, 0.02, 0.09])
flattened_weights[0].element_size()
4
# Quantization requires
# 1. zero_point: If distribution is roughly around zero. it's zero.
# 2. scale = (max_weight - min_weight) / (quantize_max - (-quanize_min))
# 3. dtype
from torch import quantize_per_tensor
dtype = torch.qint8
zero_point = 0
scale = (percentiles[-1] - percentiles[0]) / (127 - (-128))
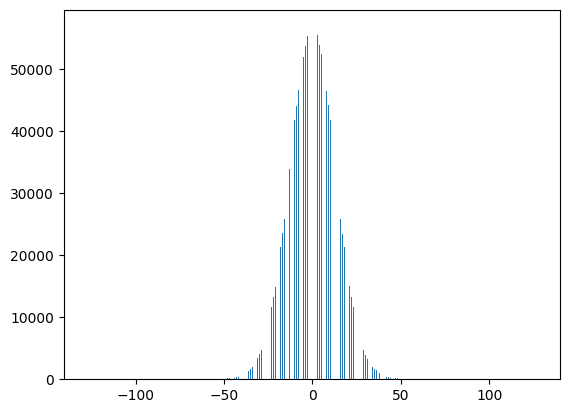
quantized_weights = quantize_per_tensor(flattened_weights.cpu(), scale, zero_point, dtype)
plt.hist(quantized_weights.int_repr(), bins=1000);
import sys
sys.getsizeof(weights.storage()) / sys.getsizeof(quantized_weights.storage())
/var/folders/k5/n4vf9c015xg33q0zpqrcr4pr0000gn/T/ipykernel_8796/2122423139.py:2: UserWarning: TypedStorage is deprecated. It will be removed in the future and UntypedStorage will be the only storage class. This should only matter to you if you are using storages directly. To access UntypedStorage directly, use tensor.untyped_storage() instead of tensor.storage()
sys.getsizeof(weights.storage()) / sys.getsizeof(quantized_weights.storage())
3.9999389660854883
linear_layers = 0
total = 0
from torch import nn
for name, module in gte_qwen_2_15b.named_modules():
if isinstance(module, nn.Linear):
linear_layers += 1
total += 1
print(f"Number of linear layers: {linear_layers}")
Number of linear layers: 196
print(gte_qwen_2_15b)
Qwen2Model(
(embed_tokens): Embedding(151646, 3584)
(layers): ModuleList(
(0-27): 28 x Qwen2DecoderLayer(
(self_attn): Qwen2Attention(
(q_proj): Linear(in_features=3584, out_features=3584, bias=True)
(k_proj): Linear(in_features=3584, out_features=512, bias=True)
(v_proj): Linear(in_features=3584, out_features=512, bias=True)
(o_proj): Linear(in_features=3584, out_features=3584, bias=False)
)
(mlp): Qwen2MLP(
(gate_proj): Linear(in_features=3584, out_features=18944, bias=False)
(up_proj): Linear(in_features=3584, out_features=18944, bias=False)
(down_proj): Linear(in_features=18944, out_features=3584, bias=False)
(act_fn): SiLU()
)
(input_layernorm): Qwen2RMSNorm((3584,), eps=1e-06)
(post_attention_layernorm): Qwen2RMSNorm((3584,), eps=1e-06)
)
)
(norm): Qwen2RMSNorm((3584,), eps=1e-06)
(rotary_emb): Qwen2RotaryEmbedding()
)
tokenizer = AutoTokenizer.from_pretrained(model_path)
# Evaluate quantized model
embedding_bench = EmbeddingBenchMark(quantized_model, qa_ds, 2, model_name="Alibaba-NLP/gte-Qwen2-7B-instruct-qt", strategy="mongo")
quantized_scores = embedding_bench.evaluate(num_samples=len(embedding_bench.qa_pairs), name="qt", save=False, model=quantized_model, collection=COLLECTION_NAME)
Generating QA Metadata for evalutaion.
Create, time embeddings and calculate similarity: 100%|███████████████████████████████████████████████| 166/166 [19:35<00:00, 7.08s/it]
quantized_scores = embedding_bench.evaluate(num_samples=len(embedding_bench.qa_pairs), name="qt", save=False, model=quantized_model, uuid="79e7edb9-9c7e-4c71-8bcd-8464c8353b7e", collection=COLLECTION_NAME)
quantized_scores
{'qt': {'latency': (1.27, 2.21), 'score': nan, 'size': '8303.027032852173 MB'}}
query_nan_count, ctx_nan_count = 0, 0
for mdata in embedding_bench.qa_pairs_metadata:
if np.isnan(mdata.query_embedding).any() == np.True_:
query_nan_count += 1
if np.isnan(mdata.context_embedding).any() == np.True_:
ctx_nan_count += 1
query_nan_count, ctx_nan_count
(250, 302)
query_embedding_nan, context_embedding_nan = 0, 0
for embedding in embedding_bench.qa_pairs_metadata:
if np.isnan(embedding.query_embedding).any() == np.True_:
query_embedding_nan += 1
if np.isnan(embedding.context_embedding).any() == np.True_:
context_embedding_nan += 1
query_embedding_nan, context_embedding_nan
(140, 166)
embedding_bench.generate_embedding(embedding_bench.qa_pairs[2][1])
array([[ 1.5376438 , 9.593268 , -2.2500036 , ..., 1.3340918 ,
2.5494578 , -0.64817363]], shape=(1, 1536), dtype=float32)
nan = 0
for qapair in embedding_bench.qa_pairs:
embedding = embedding_bench.generate_embedding(qapair[0])
if np.isnan(embedding).any() == np.True_:
nan += 1
from huggingface_hub import snapshot_download
snapshot_download(model_path)
Fetching 25 files: 0%| | 0/25 [00:00<?, ?it/s]
generation_config.json: 0%| | 0.00/117 [00:00<?, ?B/s]
config.json: 0%| | 0.00/298 [00:00<?, ?B/s]
model-00003-of-00007.safetensors: 10%|# | 503M/4.93G [00:00<?, ?B/s]
README.md: 0%| | 0.00/146k [00:00<?, ?B/s]
.gitattributes: 0%| | 0.00/1.52k [00:00<?, ?B/s]
merges.txt: 0%| | 0.00/1.67M [00:00<?, ?B/s]
config_sentence_transformers.json: 0%| | 0.00/284 [00:00<?, ?B/s]
model-00005-of-00007.safetensors: 0%| | 0.00/5.00G [00:00<?, ?B/s]
model-00004-of-00007.safetensors: 0%| | 0.00/4.93G [00:00<?, ?B/s]
model-00006-of-00007.safetensors: 0%| | 0.00/3.66G [00:00<?, ?B/s]
model-00007-of-00007.safetensors: 0%| | 0.00/2.17G [00:00<?, ?B/s]
modeling_qwen.py: 0%| | 0.00/65.2k [00:00<?, ?B/s]
added_tokens.json: 0%| | 0.00/80.0 [00:00<?, ?B/s]
modules.json: 0%| | 0.00/349 [00:00<?, ?B/s]
eval_mteb.py: 0%| | 0.00/36.2k [00:00<?, ?B/s]
sentence_bert_config.json: 0%| | 0.00/55.0 [00:00<?, ?B/s]
special_tokens_map.json: 0%| | 0.00/370 [00:00<?, ?B/s]
tokenization_qwen.py: 0%| | 0.00/10.8k [00:00<?, ?B/s]
tokenizer.json: 0%| | 0.00/7.03M [00:00<?, ?B/s]
tokenizer_config.json: 0%| | 0.00/1.31k [00:00<?, ?B/s]
vocab.json: 0%| | 0.00/2.78M [00:00<?, ?B/s]
Quantization experiment resutls:
Model: gte-Qwen-2-1.5b-instruct
- Quantizing all nn.Linear layers 5.7 -> 3.1GB. Return nan for contexts.
- Quantizing MLP nn.Linear layers 5.7 -> 5.3GB. No major advantages. Quantizing attention blocks nn.Linear layers 5.7 -> 2.5GB. Embeddings works. Attention layers are where majority of learning is done.
- MLP is computation post attention. We’ve reduced model size plus embeddings are also working.
- Not working everything is nan
Debugging Nan
# Initial setup
def quantize_fullrange(weights, dtype=torch.int8):
q_max = torch.iinfo(dtype).max
q_min = torch.iinfo(dtype).min
w_fp32 = weights.clone().to(torch.float32)
print(f"Weights shape: {w_fp32.shape}")
t_max, t_min = w_fp32.max(dim=-1), w_fp32.min(dim=-1)
print(f"max, min shape: {t_max.values.shape}, {t_min.values.shape}")
# Get scales and zero point
scales = (t_max.values - t_min.values) / (q_max - q_min)
zero_point = ((q_min - t_min.values) / scales)
scales = scales.to(dtype)
zero_point = zero_point.to(dtype)
# Zero point edge case
zero_point[zero_point < q_min] = q_min
zero_point[zero_point > q_max] = q_max
print(zero_point)
print(scales)
int8_weights = torch.round((w_fp32 / scales.unsqueeze(1)) + zero_point).to(dtype)
return int8_weights, scales, t_max, t_min, zero_point
int8_weights, scales, t_max, t_min, zero_point = quantize_fullrange(gte_qwen_2_15b.state_dict()["layers.0.self_attn.q_proj.weight"])
Weights shape: torch.Size([3584, 3584])
max, min shape: torch.Size([3584]), torch.Size([3584])
tensor([ 62, 35, -25, ..., 124, -76, -96], dtype=torch.int8)
tensor([0, 0, 0, ..., 0, 0, 0], dtype=torch.int8)
# original distribution
import matplotlib.pyplot as plt
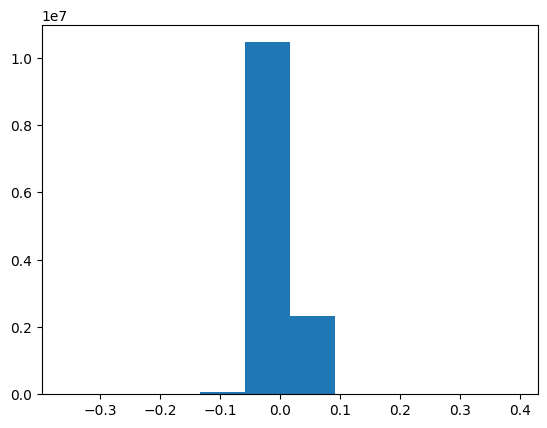
plt.hist(gte_qwen_2_15b.state_dict()["layers.0.self_attn.q_proj.weight"].flatten())
(array([1.7000000e+01, 1.1500000e+02, 1.4810000e+03, 5.6546000e+04,
1.0455893e+07, 2.3217280e+06, 8.7720000e+03, 4.5200000e+02,
4.5000000e+01, 7.0000000e+00]),
array([-0.35948557, -0.28430873, -0.20913191, -0.13395509, -0.05877826,
0.01639858, 0.09157538, 0.16675222, 0.24192905, 0.31710589,
0.39228272]),
<BarContainer object of 10 artists>)
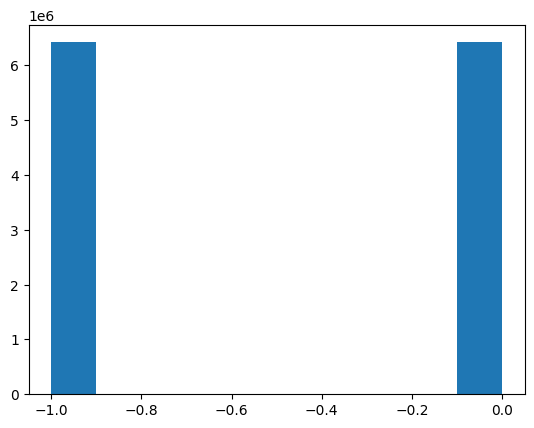
plt.hist(int8_weights.flatten())
(array([6423285., 0., 0., 0., 0., 0.,
0., 0., 0., 6421771.]),
array([-1. , -0.9, -0.8, -0.7, -0.6, -0.5, -0.4, -0.3, -0.2, -0.1, 0. ]),
<BarContainer object of 10 artists>)
# quantization error
((int8_weights.to(float) * scales) - gte_qwen_2_15b.state_dict()["layers.0.self_attn.q_proj.weight"]).square().mean()
tensor(0.0004, dtype=torch.float64)
np.percentile(int8_weights, 80)
np.float64(0.0)
Quantization error is really low, but did the quantization work? Looking at quantized distribution, percenitle, 80 percentile of quantized weights are zero. No info is retained with quantization. Why this happens? and solution?
dtype = torch.int8
q_max = torch.iinfo(dtype).max
q_min = torch.iinfo(dtype).min
man_weights = gte_qwen_2_15b.state_dict()["layers.0.self_attn.q_proj.weight"]
print(f"Weights shape: {man_weights.shape}")
t_max, t_min = man_weights.max(dim=-1).values, man_weights.min(dim=-1).values
print(f"max, min shape: {t_max.shape}, {t_min.shape}")
man_scales = (t_max - t_min) / (q_max - q_min)
print(f"Scales shape: {man_scales.shape}")
man_zero_point = ((q_min - t_min) / man_scales)
print(f"Zero point shape: {man_zero_point.shape}")
# Zero point edge case
man_zero_point[man_zero_point < q_min] = q_min
man_zero_point[man_zero_point > q_max] = q_max
# quantize weights
man_int8_weights = torch.round((man_weights / man_scales.unsqueeze(1)) + man_zero_point.unsqueeze(1)).to(dtype)
plt.hist(man_int8_weights.flatten());
Weights shape: torch.Size([3584, 3584])
max, min shape: torch.Size([3584]), torch.Size([3584])
Scales shape: torch.Size([3584])
Zero point shape: torch.Size([3584])
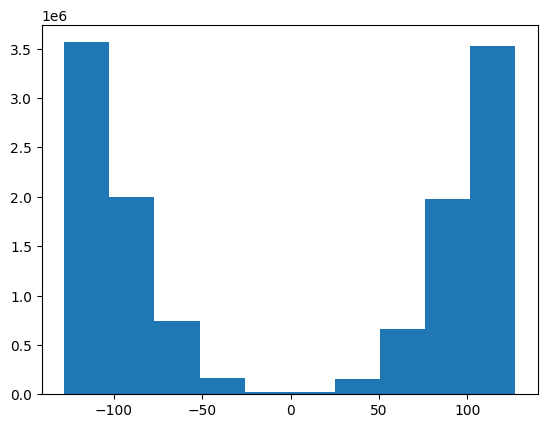
dq_weights = (man_int8_weights.to(float) - man_zero_point.unsqueeze(1)) * man_scales.unsqueeze(1)
print(f"Dequantized weights shape: {dq_weights.shape}")
(dq_weights - man_weights).square().mean()
Dequantized weights shape: torch.Size([3584, 3584])
tensor(0.0111, dtype=torch.float64)
plt.hist(dq_weights.flatten());
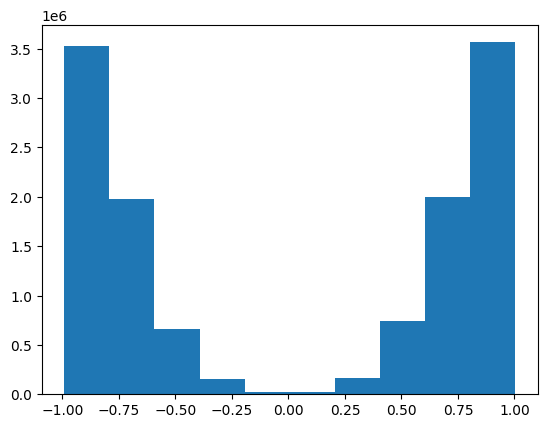
plt.hist(man_weights.flatten());
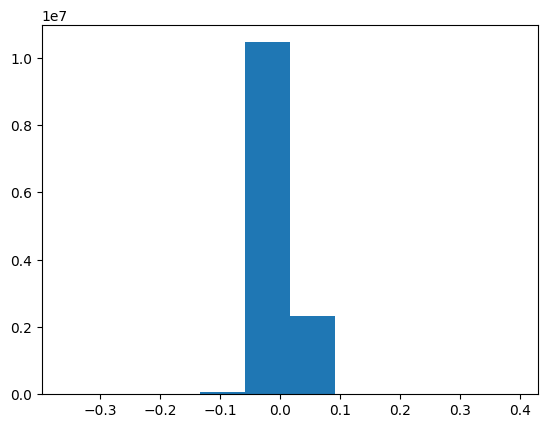
Inferences:
- absmax quantization gives nan.
- Did a detailed investigation on current fullrange quantization weights on a single layer.
- 75 percentile values are zero. With zero all pretraining knowledge is lost - - during quantization.
- Zero point addition was done without broadcasting.
- convert zero_point to row vector and add gives a better distribution not making all values to zero.
qmodel = quantize_and_store(model_path=model_path, exclude = ["lm_head", "rotary_emb"], weights_name="quantized-attention-fr.pt",)
Quantized weights are alread present: quantized-attention-fr.pt
Loading weights onto model!
Sliding Window Attention is enabled but not implemented for `sdpa`; unexpected results may be encountered.
del embedding_benchv2
gc.collect()
18
# Run evaluation
if not tokenizer:
tokenizer = AutoTokenizer.from_pretrained(model_path)
embedding_benchv2 = EmbeddingBenchMark(qmodel,tokenizer, qa_ds, 2, strategy="mongo", model_name="Alibaba-NLP/gte-Qwen2-7B-instruct-qt-fr")
qt_scores = embedding_benchv2.evaluate(num_samples=len(embedding_benchv2.qa_pairs), name="qt-fr", save=False, model=qmodel, collection=COLLECTION_NAME)
Generating QA Metadata for evalutaion.
Create, time embeddings and calculate similarity: 100%|███████████████████████████████████████████████| 166/166 [41:13<00:00, 14.90s/it]
query_nan, ctx_nan = 0, 0
for qapair in embedding_benchv2.qa_pairs_metadata:
if np.isnan(qapair.query_embedding).any() == np.True_:
query_nan += 1
if np.isnan(qapair.context_embedding).any() == np.True_:
ctx_nan += 1
query_nan
130
ctx_nan
144
Even with 7B model, verify quantization, dequantization per channel, errors etc. Still only 13 QA Pairs are without nan.
Let’s scale up the datatype to int16 instead of int8.
Let’s write a different class to handle all linear layers and update replace layers with dtype.
Before that let’s try with a different model, to see if it’s quantization problem or dataset problem!
Tried quantization with infloat mistral embeddings, code below:
tokenizer = AutoTokenizer.from_pretrained(model_path)
embedding_bench = EmbeddingBenchMark(q_model, tokenizer, qa_ds, 2, strategy="mongo", model_name="intfloat/e5-mistral-7b-instruct-qt-fr",)
embedding_bench.evaluate(num_samples=len(embedding_bench.qa_pairs), name="qt-mistral-fr", save=False, model=q_model, collection=COLLECTION_NAME)
Embeddings were still Nan.
But with a different dataset google-research-datasets/disfl_qa, Generated and checked for nan in 100 samples on both quantized models. The embeddings are fine..
The bad scores, plus Nan might be a dataset problem. On comparing these two datasets, Dataset seems is not clean, this is due to loading it from json.
del q_model
gc.collect()
9744
q_model = quantize_and_store(model_path=model_path, exclude = ["lm_head", "rotary_emb"], weights_name="quantized-attention-fr.pt", device="cpu")
Quantized weights are alread present: quantized-attention-fr.pt
Loading weights onto model!
import unicodedata, re
def clean_and_format_text(text):
"""Cleans and normalizes text to prevent tokenization errors."""
# 1. Normalize unicode characters to standard forms (NFKC for compatibility)
text = unicodedata.normalize("NFKC", text)
# 2. Remove control characters (except newlines and tabs)
text = re.sub(r'[\x00-\x08\x0b\x0c\x0e-\x1f\x7f-\x9f]', '', text)
# 3. Replace excessive newlines with a single newline (limit paragraph spacing)
text = re.sub(r'\n\s*\n+', '\n\n', text) # Max two newlines
# 4. Trim leading/trailing whitespace
text = text.strip()
# 5. Replace multiple spaces with a single space
text = re.sub(r'\s+', ' ', text)
# 6. Fix spaces after punctuation (e.g., "word,sentence" -> "word, sentence")
text = re.sub(r'([.,!?;])([^\s])', r'\1 \2', text)
# 7. Handle inconsistent quotes and special characters
text = text.replace("“", '"').replace("”", '"').replace("‘", "'").replace("’", "'")
# 8. Ensure a newline after period if not followed by proper space
text = re.sub(r'\.([A-Z])', r'. \1', text)
return text
Summary
After solving nan, let’s compare the original model results vs quantization results. Original model score will be bad because the embeddings were generated with uncleaned data(it’s compute heavy to run that again). Ignore the score. Let’s compare the latencies.
- Gte-Qwen-7B-instruct - 795f3ca7-d15a-42d2-9a91-603327205ecb - Data Uncleaned
- Gte-Qwen-7B - 7de08f07-ee83-4e1c-b149-4706bf235e3a - Data Cleaned
del original_model
gc.collect()
original_model = AutoModel.from_pretrained(model_path)
Loading checkpoint shards: 0%| | 0/7 [00:00<?, ?it/s]
tokenizer = AutoTokenizer.from_pretrained(model_path)
embedding_bench = EmbeddingBenchMark(
model=q_model,
tokenizer=tokenizer,
dataset=qa_ds,
batch_size=8,
model_name="Alibaba-NLP/gte-Qwen2-7B-instruct",
strategy="mongo"
)
q_model = quantize_and_store(model_path=model_path, exclude = ["lm_head", "rotary_emb"], weights_name="quantized-attention-fr.pt", device="cpu")
Quantized weights are alread present: quantized-attention-fr.pt
Loading weights onto model!
Sliding Window Attention is enabled but not implemented for `sdpa`; unexpected results may be encountered.
embedding_bench.evaluate(model=q_model, num_samples=embedding_bench.num_pairs, collection=COLLECTION_NAME, model_name="gte-qwen-7b-fr", eval=True, uuid="2bddd510-2e0d-411e-b32c-254fb1418a7a")
Mongo
Fetching documents from mongo
0
QAMetrics(metrics=[QAMetric(latency=(6.3, 8.4), score=1.0, size='8308.39 MB', model_name='gte-qwen-7b-fr', uuid='2bddd510-2e0d-411e-b32c-254fb1418a7a')])
original_model = AutoModel.from_pretrained(model_path)
Loading checkpoint shards: 0%| | 0/7 [00:00<?, ?it/s]
embedding_bench.evaluate(model=original_model, eval=True, uuid="795f3ca7-d15a-42d2-9a91-603327205ecb", model_name="Alibaba-NLP/gte-Qwen2-7B-instruct", collection=COLLECTION_NAME)
Mongo
Fetching documents from mongo
1
QAMetrics(metrics=[QAMetric(latency=(6.3, 8.4), score=1.0, size='8308.39 MB', model_name='gte-qwen-7b-fr', uuid='2bddd510-2e0d-411e-b32c-254fb1418a7a'), QAMetric(latency=(62.18, 63.09), score=0.38, size='26966.67 MB', model_name='Alibaba-NLP/gte-Qwen2-7B-instruct', uuid='795f3ca7-d15a-42d2-9a91-603327205ecb')])
embedding_bench.eval_results
QAMetrics(metrics=[QAMetric(latency=(6.3, 8.4), score=1.0, size='8308.39 MB', model_name='gte-qwen-7b-fr', uuid='2bddd510-2e0d-411e-b32c-254fb1418a7a'), QAMetric(latency=(62.18, 63.09), score=0.38, size='26966.67 MB', model_name='Alibaba-NLP/gte-Qwen2-7B-instruct', uuid='795f3ca7-d15a-42d2-9a91-603327205ecb')])
Latency is reduced by 10x, 8x for query and context respectivley. Ignore the scores of Original model, this run was performed on uncleaned data(Didn’t rerun due to the runtime on current hardware). Quantization yielded the desired result of reduced latency and memory footrpint plus good scores as well!
EmbeddingBenchmark Capabilites:
- Accept an EmbeddingFineTuneQADataset.
- Perform evaluation with batch or single qa pairs.
- Use mongo or local storage to save embeddings and their scores.
- skip run to resume from a failed or given point.
- Avoid generating embeddings by keeping track of current runs within instance(TODO: move to database)
- Avoid reptitive evaluations by keeping track of them.(TODO: move to database).
Distillation
Let’s distill 7B model to 1.5B to reduce the latency further. Current best latencies for query and context are 6.3s and 8.4s respectivley.
- Teacher model - gte-Qwen-7b-instruct-quantized
- Student model - gte-Qwen-1.5b-instruct
- Loss - KLDivergence + CosineSimilarity.
More details on below distillation setup and explaination
from transformers import AutoConfig, AutoTokenizer, AutoModel
teacher_model_path = model_path
student_model_path = "Alibaba-NLP/gte-Qwen2-1.5B-instruct"
teacher_config = AutoConfig.from_pretrained(teacher_model_path)
student_config = AutoConfig.from_pretrained(student_model_path)
tokenizer = AutoTokenizer.from_pretrained(teacher_model_path)
model_path
'Alibaba-NLP/gte-Qwen2-7B-instruct'
teacher_model = quantize_and_store(model_path=model_path, exclude = ["lm_head", "rotary_emb"], weights_name="quantized-attention.pt", device="cpu")
Loading checkpoint shards: 0%| | 0/7 [00:00<?, ?it/s]
class QwenDistilledModel(nn.Module):
def __init__(self, model_name, output_dim,):
super().__init__()
self.model = AutoModel.from_pretrained(model_name)
hidden_size = self.model.config.hidden_size
self.projection = nn.Linear(hidden_size, output_dim)
def forward(self, input_ids, attention_mask=None):
output = self.model(input_ids, attention_mask=attention_mask)
return self.projection(output.last_hidden_state)
# Two additional parameters alpha to determine weightage of KDLoss plus temperature to soften the logits
from transformers import TrainingArguments
class DistillationTrainingArguments(TrainingArguments):
def __init__(self, *args, alpha=0.5, temperature=2.0, **kwargs):
super().__init__(*args, **kwargs)
setattr("alpha", alpha)
setattr("temperature", temperature)
# self.alpha = alpha
# self.temperature = temperature
# Dataset
from datasets import load_dataset, Dataset, DatasetDict
ds = load_dataset("google-research-datasets/disfl_qa")
# Get original texts and contexts
ds_texts = DatasetDict({
"train": Dataset.from_dict({"text": ds["train"]["original question"] + ds["train"]["context"]}),
"test": Dataset.from_dict({"text": ds["test"]["original question"] + ds["train"]["context"]}),
"validation": Dataset.from_dict({"text": ds["validation"]["original question"] + ds["train"]["context"]}),
})
def tokenize(example):
return tokenizer(
example["text"],
padding="max_length",
truncation=True,
return_tensors="pt",
max_length=745, # 75th percentile of tokenized input ids
)
tokenized_dataset = ds_texts.map(tokenize, batched=True, remove_columns=["text"])
Map: 0%| | 0/14364 [00:00<?, ? examples/s]
Map: 0%| | 0/10825 [00:00<?, ? examples/s]
Map: 0%| | 0/8182 [00:00<?, ? examples/s]
tokenized_dataset
DatasetDict({
train: Dataset({
features: ['input_ids', 'attention_mask'],
num_rows: 14364
})
test: Dataset({
features: ['input_ids', 'attention_mask'],
num_rows: 10825
})
validation: Dataset({
features: ['input_ids', 'attention_mask'],
num_rows: 8182
})
})
# PyTorch Dataset
class DistillationDataset(torch.utils.data.Dataset):
def __init__(self, dataset):
self.dataset = dataset
def __len__(self):
return len(self.dataset)
def __getitem__(self, idx):
return self.dataset[idx]
train_dataset, test_dataset, val_dataset = DistillationDataset(tokenized_dataset["train"]), DistillationDataset(tokenized_dataset["test"]), DistillationDataset(tokenized_dataset["validation"])
train_dataset[1].keys()
dict_keys(['input_ids', 'attention_mask'])
# Distillation Loss
class DistillationLoss(nn.Module):
def __init__(self, alpha=0.5, temperature=2.0):
super().__init__()
self.alpha = alpha
self.temperature = temperature
self.kl_loss = nn.KLDivLoss(reduction="batchmean")
self.cosine_loss = nn.CosineEmbeddingLoss()
def forward(self, student_embeddings, teacher_embeddings):
kl_loss = self.kl_loss(
F.log_softmax(student_embeddings / self.temperature, dim=-1),
F.softmax(teacher_embeddings / self.temperature, dim=-1)
)
target = torch.ones(student_embeddings.shape[0], device=student_embeddings.device) # Ones, cosine similarity, if closer to ones they are better
cosine_loss = self.cosine_loss(student_embeddings, teacher_embeddings, target)
return self.alpha * kl_loss + (1 - self.alpha) * cosine_loss
class DistillationTrainingArguments(TrainingArguments):
def __init__(self, *args, alpha=0.5, temperature=2.0, **kwargs):
self.alpha = alpha
self.temperature = temperature
super().__init__(*args, **kwargs)
# Custom Trainer
from transformers import Trainer
class DistillationTrainer(Trainer):
def __init__(self, *args, teacher_model=None, device="cpu", **kwargs):
super().__init__(*args, **kwargs)
self.teacher_model = teacher_model
self.loss = DistillationLoss(self.args.alpha, self.args.temperature)
def compute_loss(self, model, inputs, return_outputs=False, **kwargs):
output_stu = model(**inputs)
stu_hs = output_stu.last_hidden_states
# Teacher model is not required in backpropogation
with torch.autocast(dtype=torch.bfloat16):
outputs_tea = self.teacher_model(**inputs)
tea_hs = outputs_tea.last_hidden_states
return (loss, stu_hs) if return_output else loss
def student_init():
return QwenDistilledModel(model_name=student_model_path, output_dim=teacher_config.hidden_size)
training_args = DistillationTrainingArguments(
output_dir="./checkpoints",
alpha=0.5,
temperature=2.0,
evaluation_strategy="epoch",
num_train_epochs=5,
learning_rate=2e-5,
per_device_train_batch_size=8,
per_device_eval_batch_size=8,
weight_decay=0.01,
save_strategy="epoch",
save_total_limit=2,
)
/Users/j.chinnarajii/miniconda3/envs/py310/lib/python3.10/site-packages/transformers/training_args.py:1594: FutureWarning: `evaluation_strategy` is deprecated and will be removed in version 4.46 of 🤗 Transformers. Use `eval_strategy` instead
warnings.warn(
# del trainer
# gc.collect()
trainer = DistillationTrainer(
model_init=student_init,
args=training_args,
train_dataset=tokenized_dataset["train"].select(range(256)),
eval_dataset=tokenized_dataset["validation"].select(range(256)),
teacher_model=teacher_model,
)
Loading checkpoint shards: 0%| | 0/2 [00:00<?, ?it/s]
trainer.train()
Ran out of memory and comput in distillation training run. The script should work fine in a cluster. Better strategies would be, quantize teacher model with fp16(update quantization setup for different dataytpes) and then perform distillation run. For distillation setup and more details refer notebook.